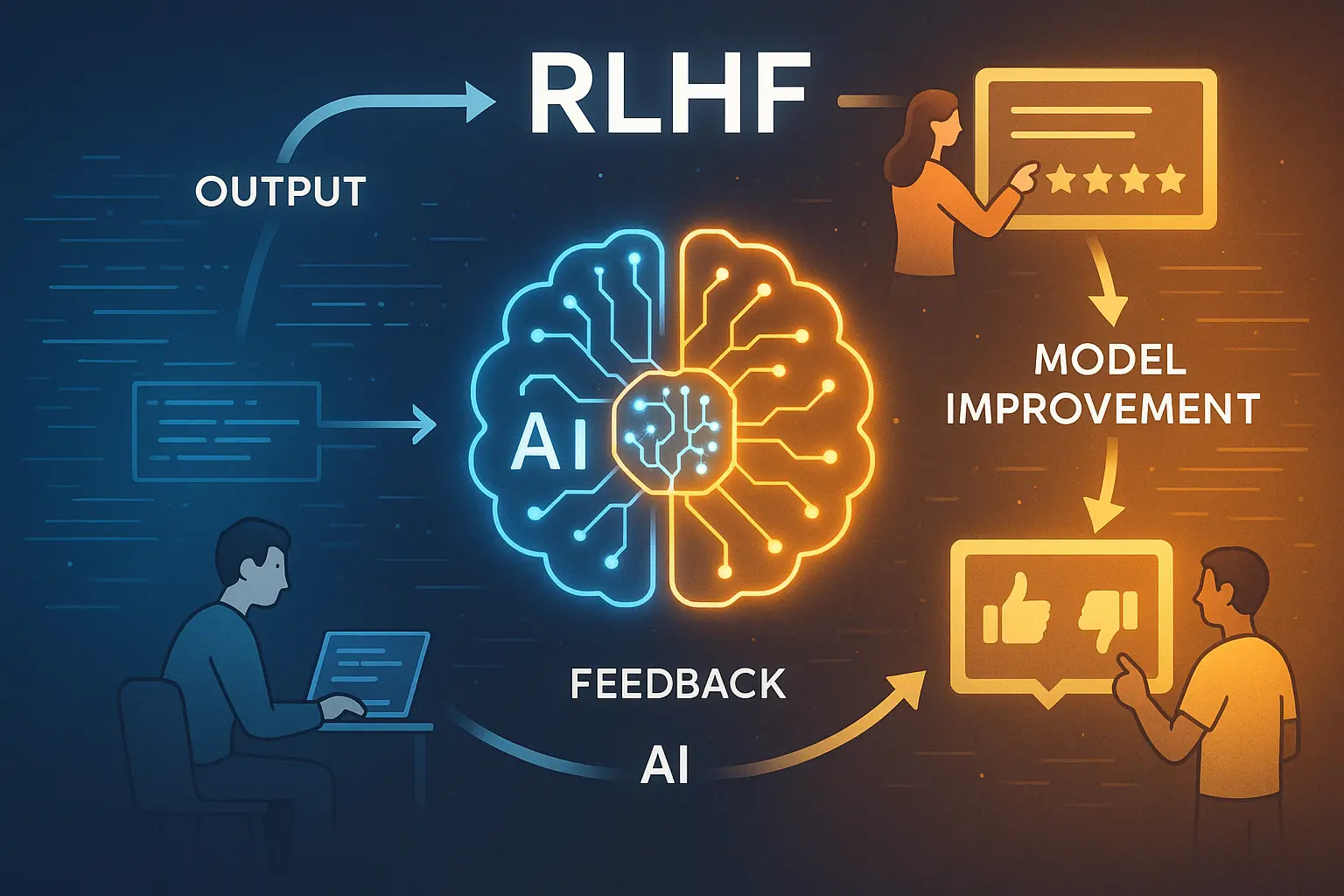
2026 04-23 本文是LLM强化学习后训练系列的第二篇,主要介绍GPT所使用的RLHF(Reinforcement Learning with Human Feedback)方法。RLHF是一种结合了人类反馈的强化学习方法,旨在提升LLM在特定任务上的表现。 后一篇 LLM强化学习后训练系列(一)-- 前置知识
说些什么吧!