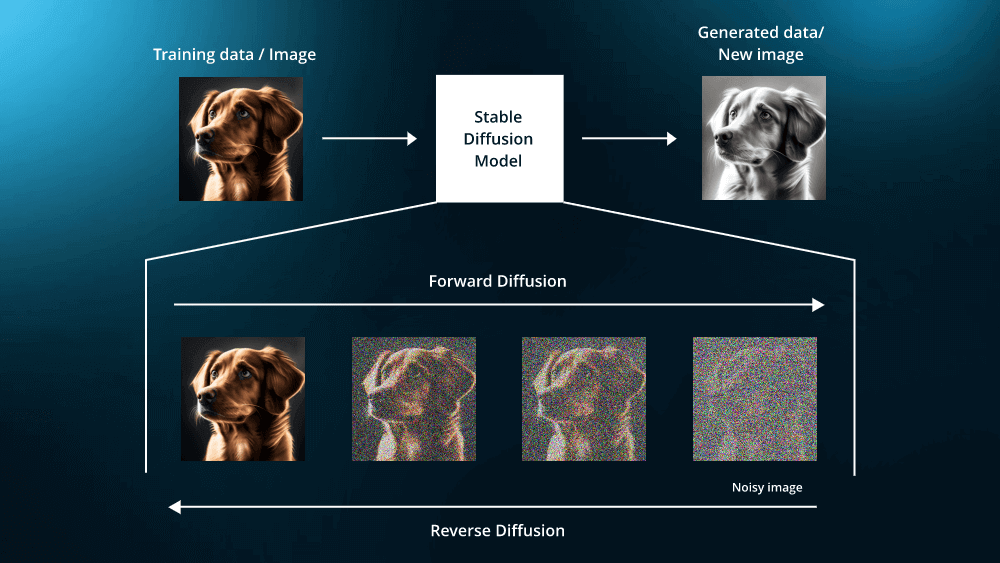
本文是LLM后训练的第五篇,介绍了两种基于LLM强化学习的后训练方法:GRPO(Generalized Reward Policy Optimization)和DPO(Direct Preference Optimization)。
本文是LLM后训练的第四篇,从这篇开始,会介绍LLM的后训练。而本篇章主要介绍基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF)以及PPO算法在RLHF中如何应用。
本文是LLM后训练的第三篇,主要介绍近端策略优化(Proximal Policy Optimization,简称PPO)算法。PPO算法在LLM后训练中起到举足轻重的作用。PPO算法更像是一个强化学习技巧的集合体,其设计重点在于保证训练的稳定性。因此在介绍PPO算法之前,需要先了解其背后的一些基础背景。
本文是LLM后训练的第二篇,主要介绍强化学习中价值函数以及Advantage Actor-Critic模型(A2C)。 奖励信号的构造方式 在LLM后训练(一)中,我们介绍了强化学习的基本概念和一些常用的算法,并介绍了最原始的奖励损失函数:
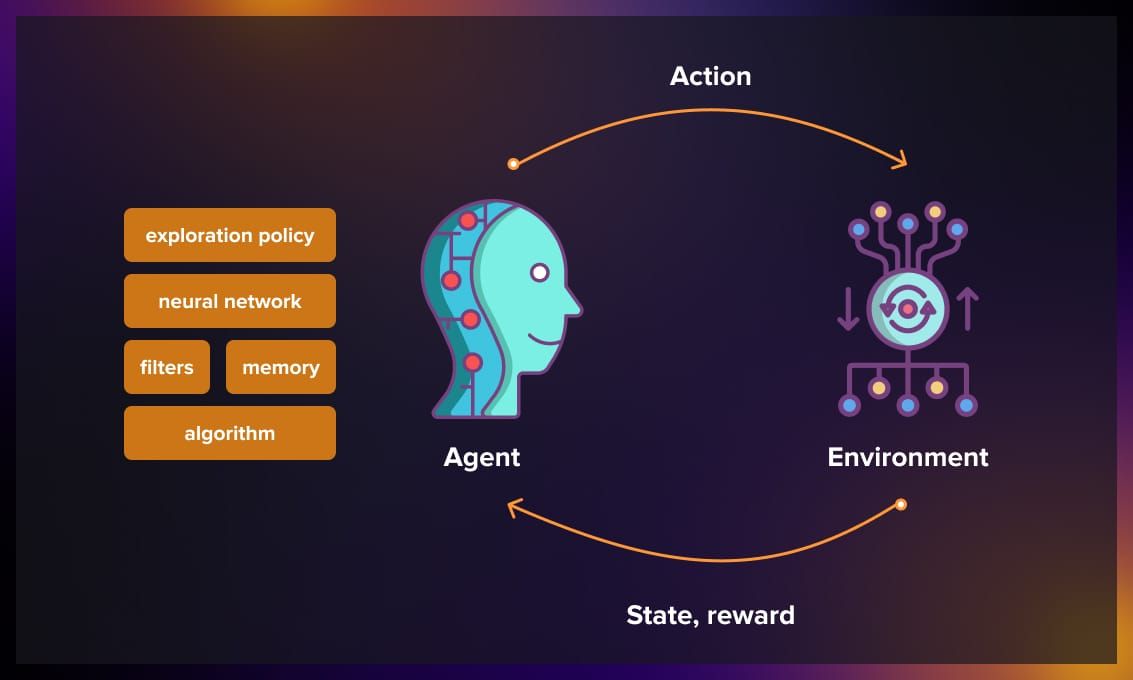
本为 LLM 强化学习后训练梳理与总结。其脉络沿着强化学习的基本概念、算法原理、改进策略、以及在大语言模型后训练中的应用展开。不会涵盖强化学习的所有内容,而是聚焦于与大语言模型后训练相关的部分。主要是理清大语言模型后训练中强化学习的核心逻辑和思路。