本系列为 LLM 强化学习后训练梳理与总结。
强化学习
1. 背景
强化学习(Reinforcement Learning)是机器学习的一个重要分支,它关注智能体如何在环境中采取行动以最大化某种累积奖励。与监督学习不同,强化学习通常没有标记好的“正确答案”,而是通过试错和延迟奖励来学习最优策略。
强化学习的灵感来源于心理学中的行为主义理论,即生物体通过与环境交互,根据行动产生的后果(奖励或惩罚)来调整自身的行为。这种学习范式使得智能体能够在未知且动态的环境中进行决策,被广泛应用于机器人控制、游戏博弈、自动驾驶和推荐系统等领域。
强化学习的分类如下图所示:
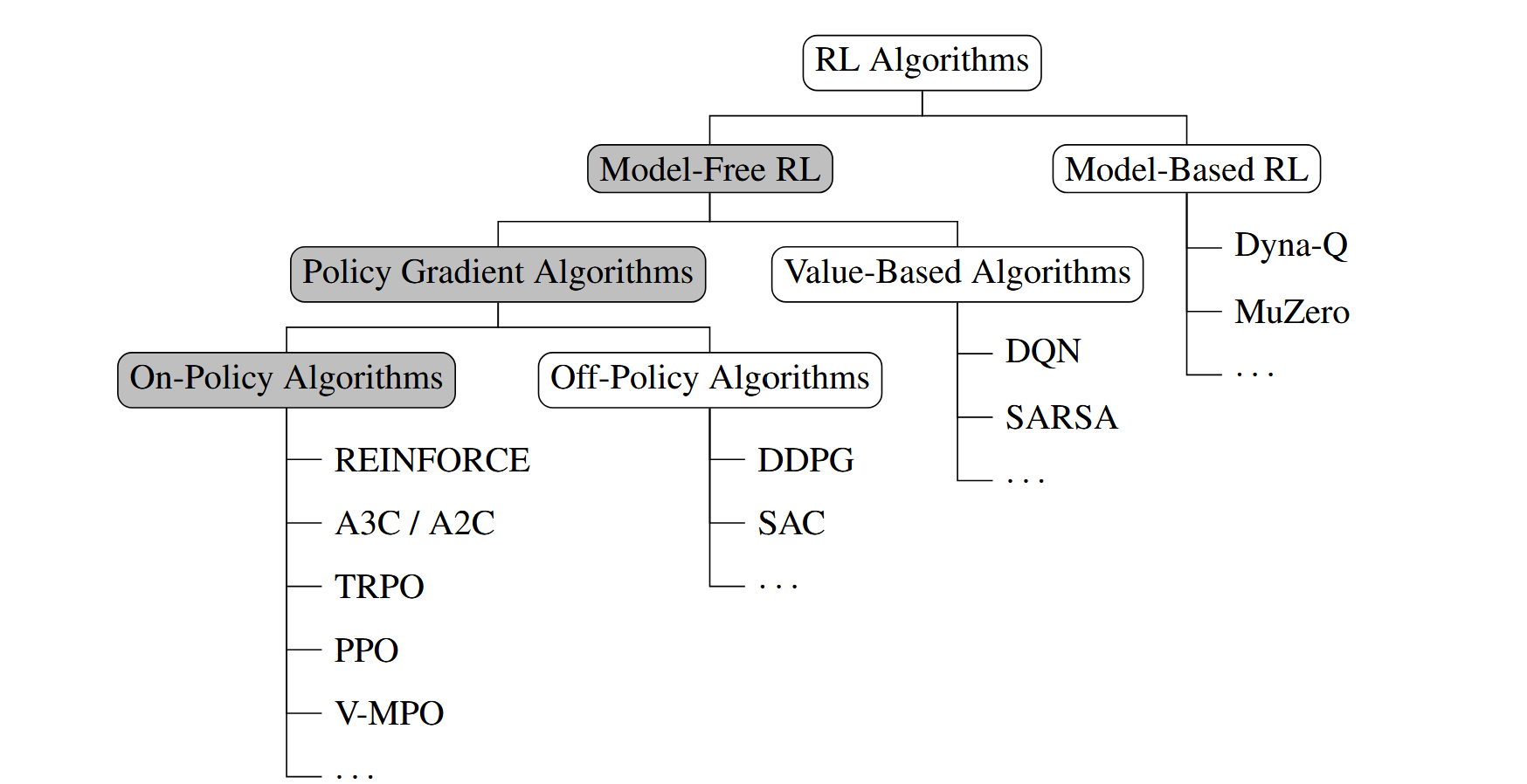
(注:上图来源于,分类不一定准确,比如Q-Learning也可以算是基于策略的模型)
本系列主要对大模型后训练中用到的 on-policy 算法进行总结和分析。在此之前,先介绍强化学习的一些基本概念。
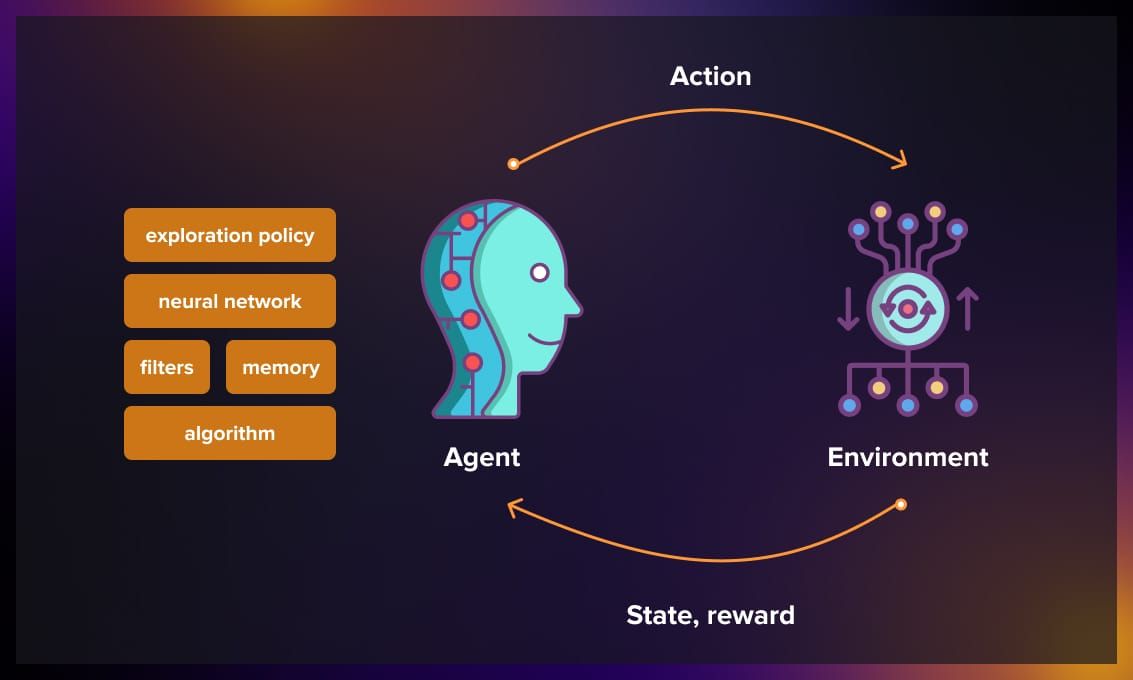
一个标准的强化学习系统由以下核心要素组成:
- 智能体:进行学习和决策的主体。
- 环境:智能体所处的外部世界。
- 动作:智能体可以执行的操作。
- 状态:对环境情况的描述。
- 奖励:环境反馈给智能体的标量信号,用于评价动作的好坏。
2. 环境状态
环境状态是强化学习中最基础的概念之一。它是对环境在某一时刻的完整描述,包含了决定未来发展所需的所有信息。
通常用符号 表示时刻 的状态。智能体的目标通常是根据观测到的状态序列,选择最优的动作序列。状态的获取方式通常有两种:
- 完全可观测:智能体能直接感知到环境的真实状态 。
- 部分可观测:智能体只能接收到观测值 ,观测值可能不包含环境的所有信息(例如,由于视野受限或噪声干扰)。在这种情况下,智能体通常需要维护内部的“信念状态”或历史记录来做决策。
在数学上,强化学习过程通常被建模为马尔可夫决策过程 (MDP)。如果状态满足马尔可夫性质,即“未来状态仅依赖于当前状态和当前动作,而与过去的历史无关”,那么该状态是最理想的。
3. 奖励函数
奖励函数是强化学习的核心,它定义了强化学习问题追求的量化目标。
在每一个时间步 ,环境会根据智能体的动作 和当前状态 ,反馈一个标量数值 。智能体的终极目标是最大化长期累积奖励。
累积奖励通常通过回报 (Return) 来计算,最常见的计算方式是折扣累积回报,定义如下:
其中, 是折扣因子。
- 接近 0 时,智能体主要关注即时奖励(短视)。
- 接近 1 时,智能体更关注长远的未来奖励(远视)。
以上为理想情况。在实际任务中,我们并不能直接获得每一时刻的奖励,比如在棋牌游戏和大语言模型等任务中,可能仅在个别时刻或最后时刻才能获得一个奖励信号。例如,围棋需要下到最后才能知道输赢,语言模型需要输出完整答案才能获得评分,无法针对每个 token 进行直接打分。
4. 基于值的模型
基于值的方法的核心思想是不直接学习策略,而是学习一个价值函数,用来估算处于某个状态或在某个状态下执行某个动作的“价值”。
主要有两种价值函数:
-
状态价值函数 ():表示智能体遵循某个策略 时,从状态 开始预期的累积回报。
-
动作价值函数 ():也称为 Q 值,表示在状态 下执行动作 ,之后遵循策略 的预期累积回报。
贝尔曼方程是基于值方法的基础,它表达了当前状态的价值与下一状态价值之间的递推关系:
典型算法:
- Q-Learning:经典的异策略算法,通过维护一张 Q 表来记录价值。
- DQN (Deep Q-Network):利用深度神经网络来拟合 Q 函数,解决高维状态空间问题。
基于值的方法通常通过贪婪策略来生成决策:选择价值函数估计最高的动作 。基于值的模型本系列不再详细展开,重点分析基于策略的模型。
5. 基于策略的模型
基于策略的方法直接对策略 进行建模。策略通常被参数化表示为 ,其中 是策略网络的参数。这种方法输出的是在给定状态下采取各个动作的概率分布。
5.1 策略梯度
策略梯度是一类直接优化策略参数 的方法。其核心思想是:如果某个动作导致了正向的回报,那么就增加该动作在当前状态下被选中的概率;反之则降低概率。
我们假设已经给定了一个策略分布 ,这个策略可以是当前被训练的智能体产生的策略 (on policy),或者另外定义的一个策略分布(off policy)。本系列默认这个策略分布就是当前被训练智能体的策略 。
首先,从 逐步生成动作并在生成过程中不断与环境交互,最终得到一系列采样轨迹(或称为 Episode,回合)。
通常表示为 ,其中 表示状态, 表示动作, 表示奖励, 表示终止时刻。采样过程实际上是一个马尔可夫过程,其概率表示为:
累计奖励为:
因此其获得回报的数学期望为:
将该期望作为目标函数 ,我们希望通过调整 来最大化 。
我们的目标是最大化目标函数 (即期望回报)。根据策略梯度定理,梯度的计算公式如下:
实际训练过程需要通过经验采样来代替期望计算,即通过多次采样轨迹 来估计梯度:
可以看出上述求解梯度的公式实际上等价于一个交叉熵损失函数的优化过程:
- :表示增加该动作概率的梯度方向。
- :表示回报,用作权重。
直观理解:
- 如果某一步的回报 很高,就在梯度方向上增大该动作的概率。
- 如果回报 很低,就减小该动作的概率。
典型算法:
- REINFORCE:基于蒙特卡洛采样的策略梯度方法。
- PPO (Proximal Policy Optimization):近端策略优化,通过限制新旧策略的差异来保证训练的稳定性。
在实际问题中,直接使用 作为权重可能会导致训练不稳定:一方面回报具有较大的方差,另一方面有些回报虽然大于零,但并不一定比其他动作更好,从统计决策角度讲应当视为交叉熵中的负样本。因此,引入优势函数来降低方差并加速收敛。
6. 优势函数
在策略梯度方法中,直接使用回报作为权重往往存在方差过大的问题,导致训练不稳定。为了解决这个问题,引入了优势函数。
优势函数 的定义是:在状态 下采取动作 ,比采取该状态下“平均”动作要好多少。
其数学表达式为:
- :采取该动作的实际价值。
- :该状态下所有动作按策略执行的平均价值(即基准线 Baseline)。
引入优势函数的作用:
- 减少方差:它衡量的是一个动作相对于平均水平的“优势”,而不是所有动作的绝对奖励和。这能防止在所有动作价值普遍较高或较低时产生的误判。
- 加速收敛:通过归一化效果,帮助智能体更快地识别出真正优秀的动作。
在诸如 A3C (Asynchronous Advantage Actor-Critic) 等高级算法中,优势函数是连接“Actor”(策略网络)和“Critic”(价值网络)的关键桥梁。
说些什么吧!