本文是LLM后训练的第四篇,从这篇开始,会介绍LLM的后训练。而本篇章主要介绍基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF)以及PPO算法在RLHF中如何应用。
LLM的训练阶段
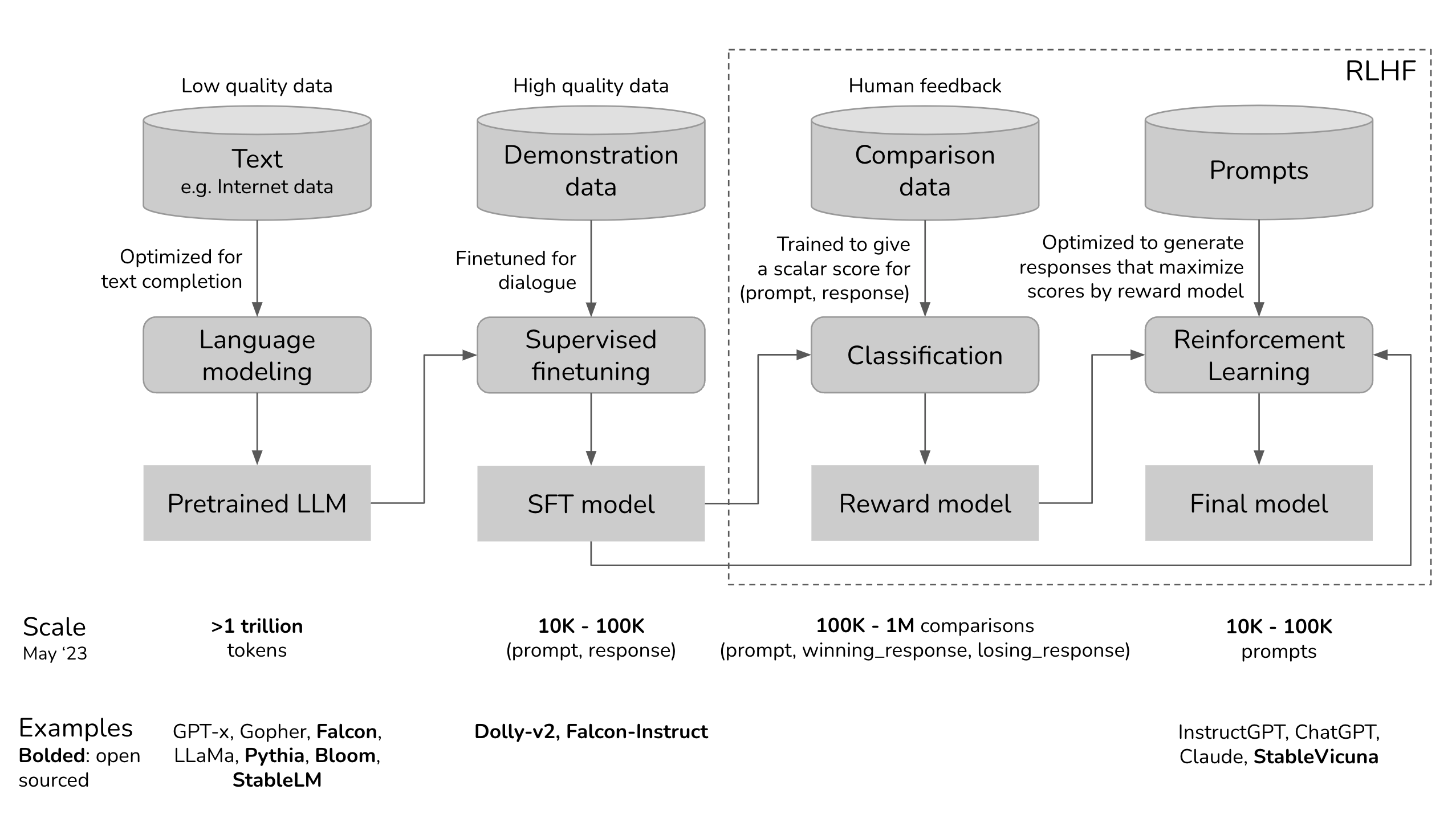
在介绍RLHF之前,我们先回顾一下LLM的训练阶段。LLM的训练通常分为三个阶段:
- 预训练(Pre-training):在这个阶段,模型通过大量的文本数据进行训练,学习语言的基本结构和语义。训练完成后模型可以够生成连贯的文本,但可能缺乏特定任务以及指令遵从能力。
- 有监督微调(Supervised Fine-tuning, SFT):在这个阶段,模型主要学会指令遵从能力以及下游特定任务的能力。训练数据通常是人类编写的指令-响应对,模型通过模仿这些对话来学习如何更好地理解和执行指令。
- 强化学习(Reinforcement Learning, RL):在这个阶段,模型通过强化学习来进一步优化其性能(例如对齐人类偏好,使其说话语气更接近人类。或者提高代码和数学能力)。RLHF是强化学习的一种方法,它利用人类反馈来指导模型的学习过程。
前两个阶段本文不再介绍,下面用强化学习的视角来介绍RLHF。
强化学习视角下的LLM
在LLM后训练(一)中提到,一个完整的强化学习系统主要包括智能体,环境,状态,动作以及奖励。在LLM的强化学习阶段中,模型可以视为智能体,环境和状态可以视为模型的输入以及已经输出的上下文,动作可以视为模型的当前时刻输出的token,奖励则是根据模型输出的文本质量靠人类或者额外的模型进行评估。下面结合可视化以及PPO详细介绍一下LLM强化学习中的要素:
智能体,环境和状态,和动作
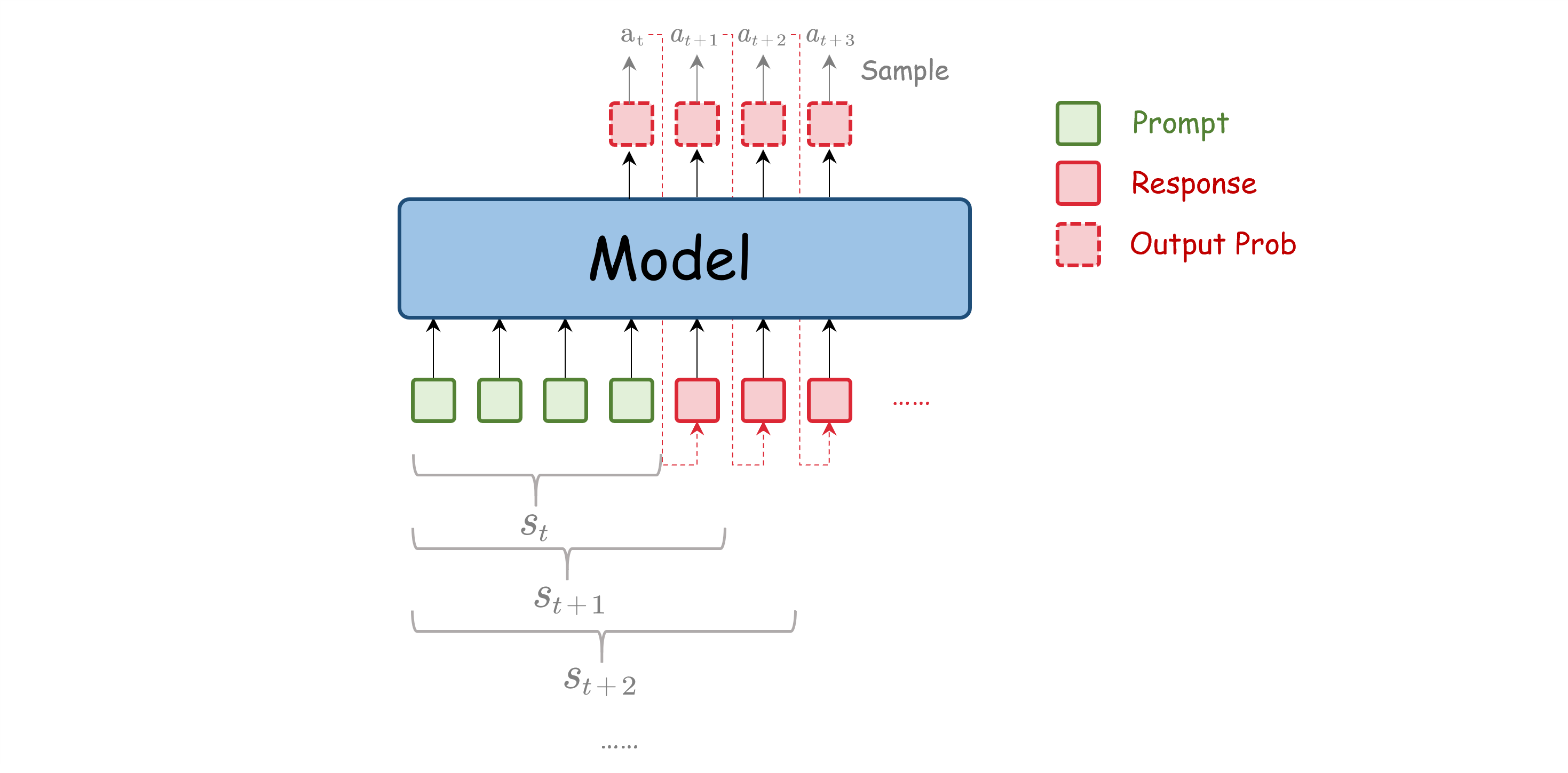
LLM为智能体,环境和状态就包含了输入的prompt(包括special token、用户输入的token以及工具调用的token等)以及已经输出的token。动作$a_t$则是模型在步骤t采样输出的token。对于LLM来说,离散动作空间相当于是词表的大小,通常是非常大的。而策略$\pi_\theta(a_t|s_t)$则是模型在状态$s_t$下采样动作$a_t$的概率分布,即模型最后一层softmax输出的概率分布, $\theta$为模型的参数。由于LLM自回归的特性,模型每次输出后都会将输出的token直接加入到下一步的环境中,形成新的状态。
Actor model & Reference Model
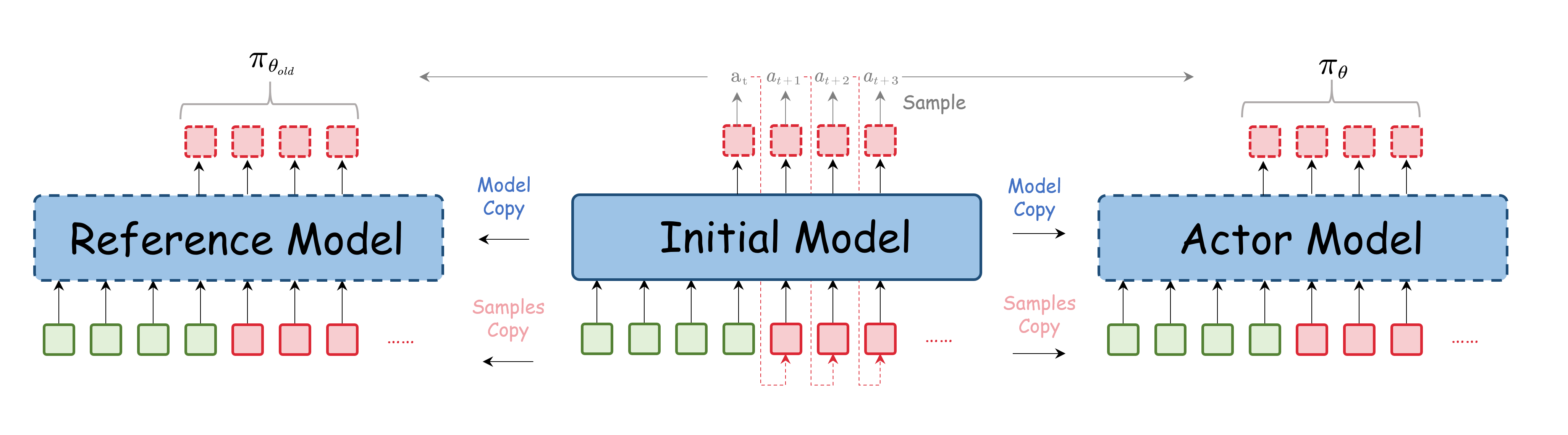
在LLM后训练(三)中提到,PPO需要阶段性地rollout,即需要在$\pi_{\theta_{old}}$上采样生成动作,更新$\pi_{\theta}$模型, $\pi_{\theta_{old}}$ 即为reference model, 作用是提供一个稳定的基准,防止模型在训练过程中发生过大的更新,从而保持训练的稳定性。Reference model一般是SFT输出的模型(即RL阶段最初的模型)。Policy model为更新前的actor model,在每轮更新周期内,policy model对给定prompt进行采样生成动作,并根据奖励信号对actor进行更新。由于采样速度较慢,为了提高数据利用效率,对actor model的使用同一批数据进行多次更新,在多次更新后将模型同步回policy model,然后用新的policy model 进行下一轮采样。在代码实现中,actor model和policy model通常只需要维护同一套权重。而Reference model则需要单独维护一套权重,且在训练过程中保持不变(但是在部分模型中比如DeepSeek会间隔一定步数和actor model进行同步)。
Reward Model
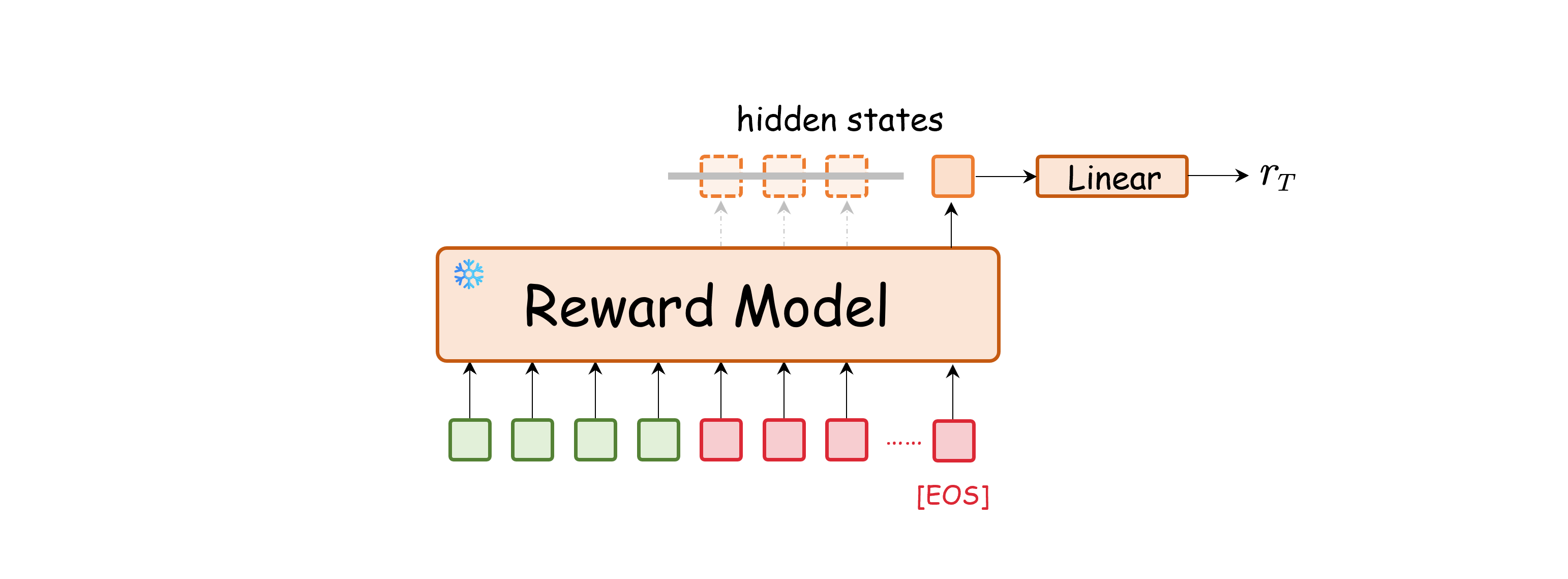
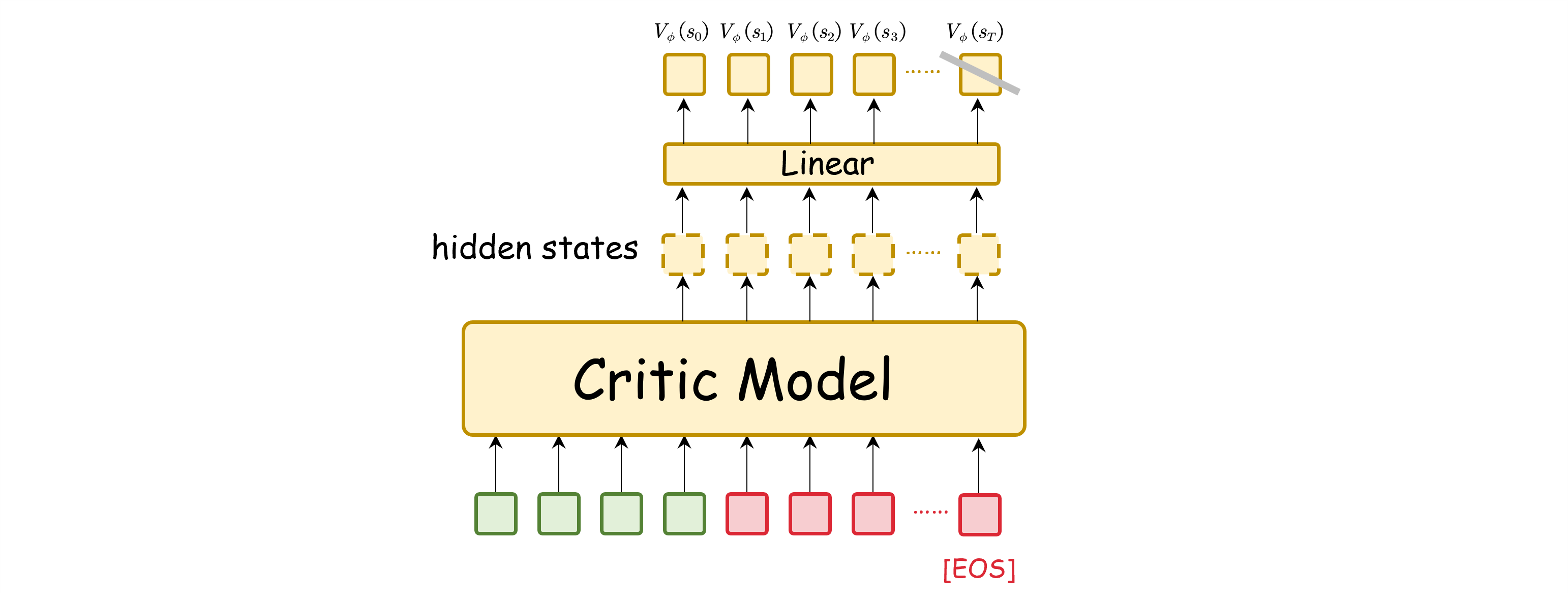
Critic Model
a
说些什么吧!