本文是LLM后训练的第四篇,从这篇开始,会介绍LLM的后训练。而本篇章主要介绍基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF)以及PPO算法在RLHF中如何应用。
LLM的训练阶段
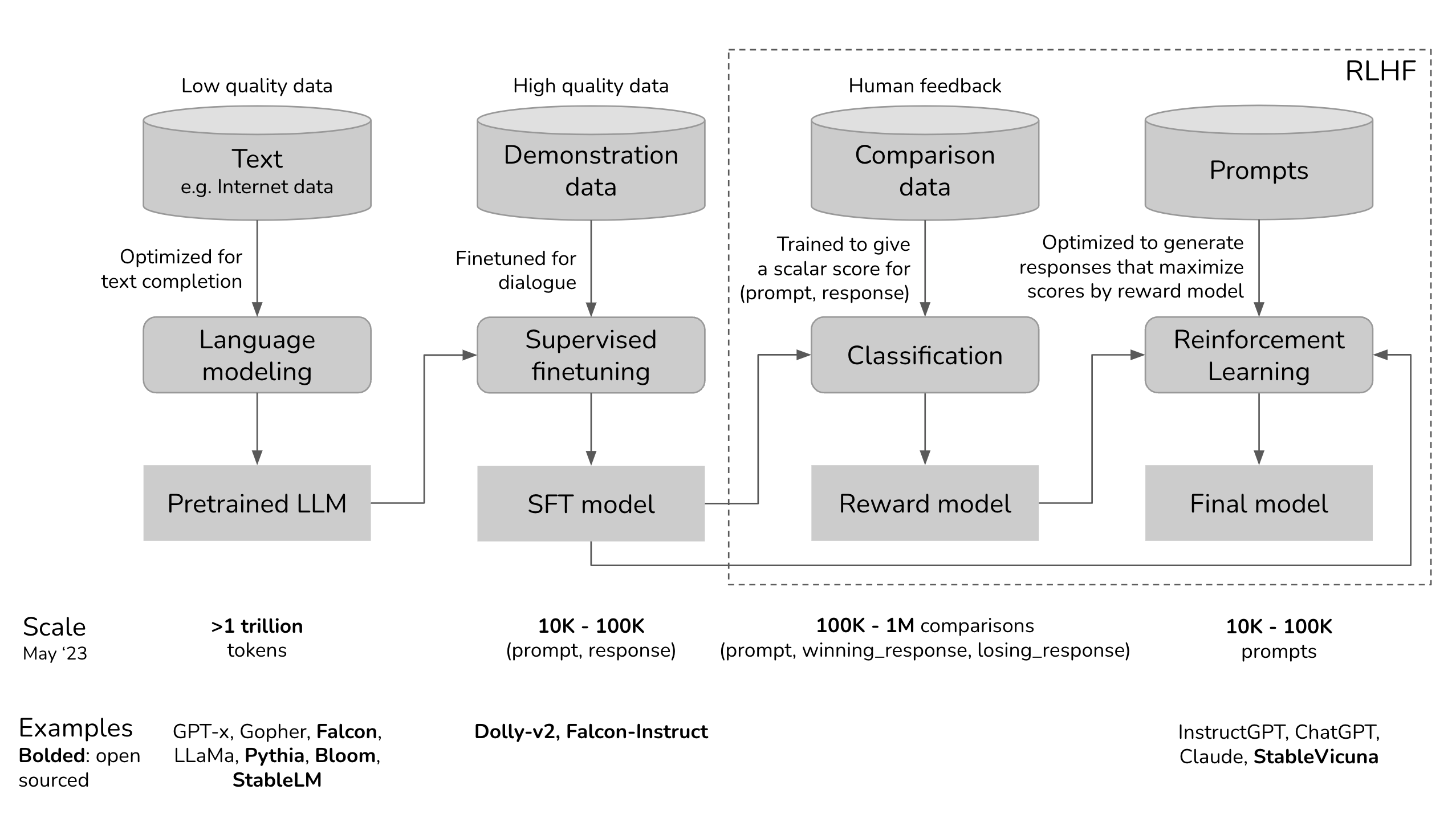
在介绍RLHF之前,我们先回顾一下LLM的训练阶段。LLM的训练通常分为三个阶段:
- 预训练(Pre-training):在这个阶段,模型通过大量的文本数据进行训练,学习语言的基本结构和语义。训练完成后模型可以够生成连贯的文本,但可能缺乏特定任务以及指令遵从能力。
- 有监督微调(Supervised Fine-tuning, SFT):在这个阶段,模型主要学会指令遵从能力以及下游特定任务的能力。训练数据通常是人类编写的指令-响应对,模型通过模仿这些对话来学习如何更好地理解和执行指令。
- 强化学习(Reinforcement Learning, RL):在这个阶段,模型通过强化学习来进一步优化其性能(例如对齐人类偏好,使其说话语气更接近人类。或者提高代码和数学能力)。RLHF是强化学习的一种方法,它利用人类反馈来指导模型的学习过程。
前两个阶段本文不再介绍,下面用强化学习的视角来介绍RLHF。
强化学习视角下的LLM
在LLM后训练(一)中提到,一个完整的强化学习系统主要包括智能体,环境,状态,动作以及奖励。在LLM的强化学习阶段中,模型可以视为智能体,环境和状态可以视为模型的输入以及已经输出的上下文,动作可以视为模型的当前时刻输出的token,奖励则是根据模型输出的文本质量靠人类或者额外的模型进行评估。下面结合可视化以及PPO详细介绍一下LLM强化学习中的要素:
智能体,环境和状态,和动作
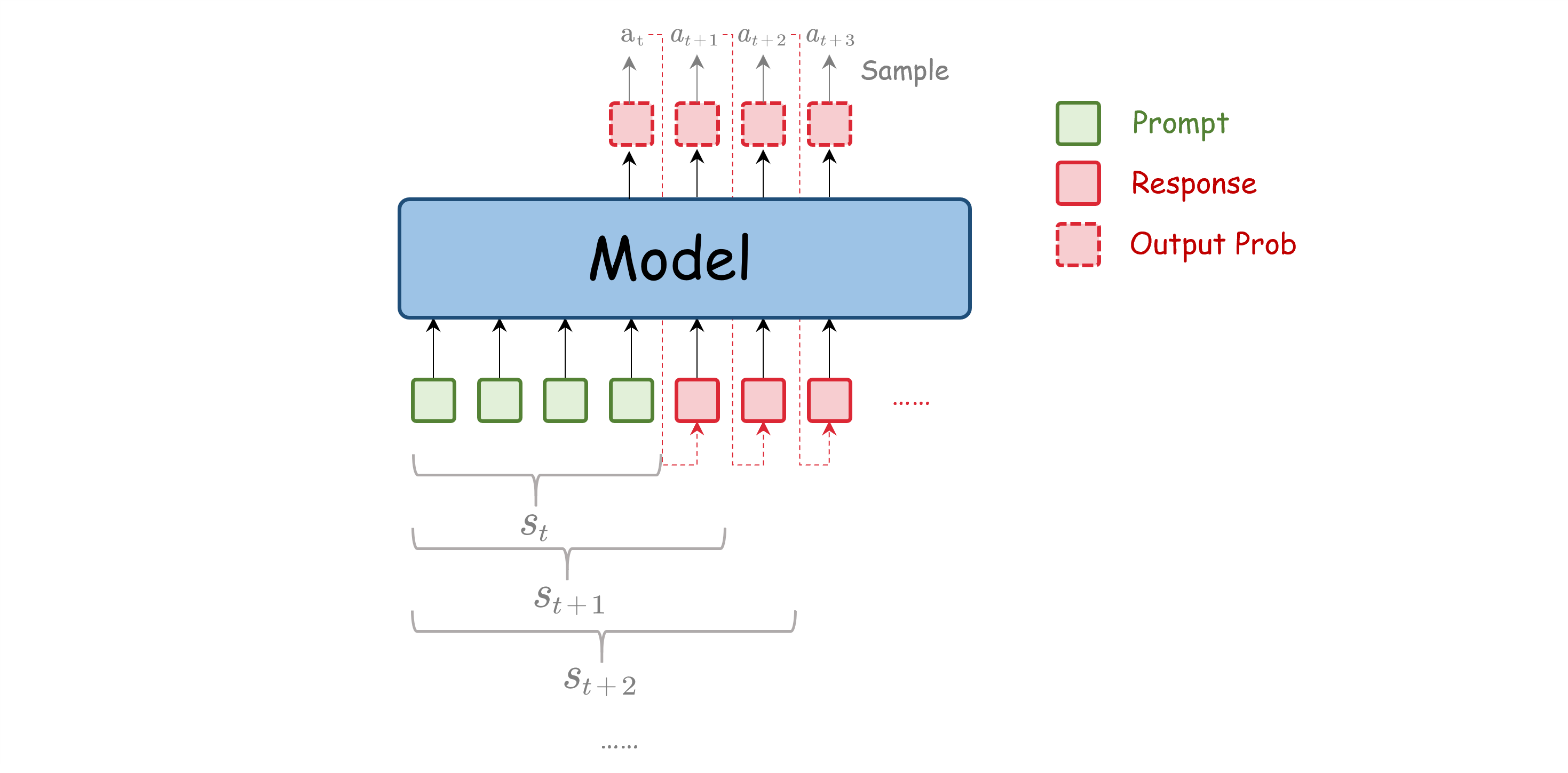
LLM为智能体,环境和状态就包含了输入的prompt(包括special token、用户输入的token以及工具调用的token等)以及已经输出的token。动作则是模型在步骤t采样输出的token。对于LLM来说,离散动作空间相当于是词表的大小,通常是非常大的。而策略则是模型在状态下采样动作的概率分布,即模型最后一层softmax输出的概率分布, 为模型的参数。由于LLM自回归的特性,模型每次输出后都会将输出的token直接加入到下一步的环境中,形成新的状态。
Actor model & Reference Model
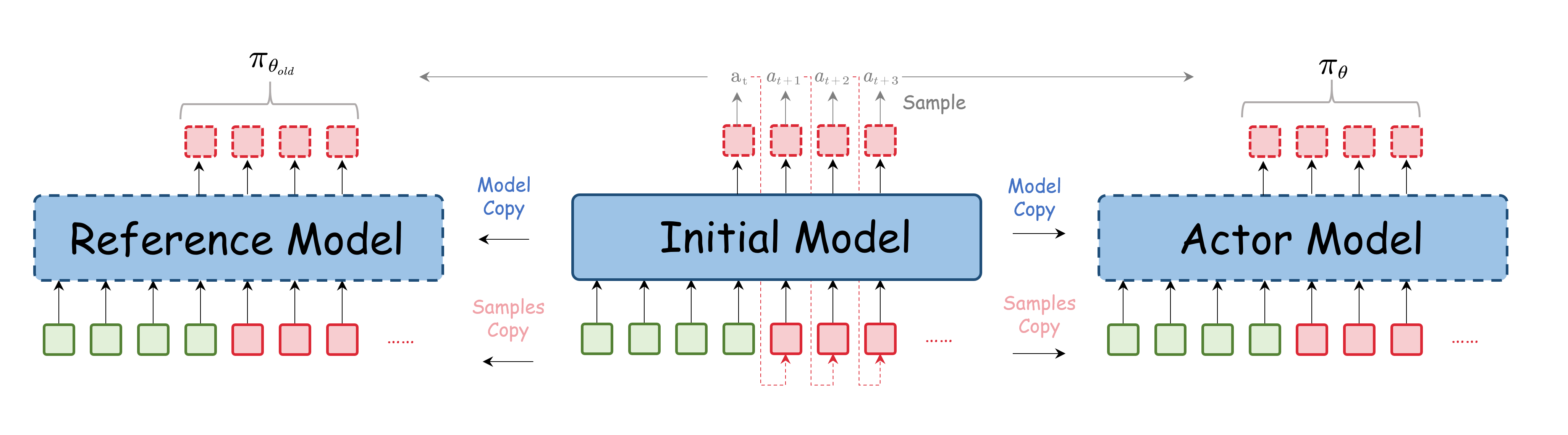
在LLM后训练(三)中提到,PPO需要阶段性地rollout,即需要在上采样生成动作,更新模型, 即为reference model, 作用是提供一个稳定的基准,防止模型在训练过程中发生过大的更新,从而保持训练的稳定性。Reference model通常是本轮初始策略模型的一个副本。同时一次性rollout多个数据进行多次梯度下降更新Actor权重。图中为了方便理解概念,采用了另一种等价的做法,先对初始模型rollout一批动作样本,然后再分别将权重复制为actor model和reference model并分发采样数据。实际上reference Model和初始Model本质上是同一套权重,只需要保存一份权重并进行一组前向计算就可以得到采样数据以及旧策略概率分布,即初始模型同时承担rollout和reference的作用,数据也只需要copy一次给actor model即可。
在每轮更新周期内actor model不再与环境进行交互,只用每轮开始时采样好的数据以及奖励信号进行梯度更新。
Reward Model
Critic Model
a
说些什么吧!